
The Two Claudes Pattern: Chat for Thinking, Code for Building
Part 3 of 7 in the Heikin Ashi series.
The previous two posts described a Heikin Ashi monitoring service built on AWS Lambda with Java 25, and the design conversation that produced its specifications. This one describes the workflow pattern that emerged for actually building and maintaining it: Claude chat for architecture and decisions, Claude Code for implementation, with CLAUDE.md as the shared specification that keeps both aligned. It also describes the situations in which the pattern doesn’t work and shouldn’t be used.
I call it the Two Claudes pattern, for lack of a better name.
The two roles
| Tool | Surface | Best at |
|---|---|---|
| Claude (chat.com / mobile app) | conversational | architecture, decisions, brainstorming, refactoring proposals, writing prose deliverables (specs, docs, blog posts) |
| Claude Code | command-line, in the repo | reading and writing files, running commands, iterating on a codebase, debugging, implementing specs |
They’re both Claude. They share underlying capabilities. The differences come from what each surface gives them access to.
Chat Claude can’t read your repo. Claude Code can. Chat Claude can have a long, exploratory conversation about whether a decision is right. Claude Code is much more efficient at applying that decision once made. Chat Claude is great at producing the deliverable that explains why. Claude Code is great at producing the deliverable that is (working code).
Why split the work
The temptation, when you have access to both, is to use Claude Code for everything: it can edit files, run tests, even run web searches now. Why bother with a separate chat?
Three reasons:
-
Context budget. Claude Code’s context fills up with file contents, command outputs, diffs. A long architectural discussion in that environment crowds out the room it needs for actually working with code. Better to do the discussion elsewhere and bring back the result.
-
Decisions deserve their own space. When you’re debating whether to use single-table or multi-table DynamoDB, you don’t want the model also tracking the state of the build, the open files, the recent commits. The discussion benefits from focused attention.
-
Specs become artifacts. A design conversation in chat ends with prose you can save, version, share. The same conversation embedded inside a coding session is harder to extract.
The bridge: CLAUDE.md and context bundles
Two artifacts move information between the two Claudes:
-
CLAUDE.mdlives at the root of the repo. Claude Code reads it automatically at the start of every session. It contains the architectural decisions, the data model, the domain operations as Gherkin scenarios, the error catalog, the test strategy, the IaC plan, the code style conventions. Everything that isn’t code but constrains how code should be written. -
A context bundle is a small markdown file generated on demand by Claude Code, summarizing the current state of the project. Stuff that isn’t in
CLAUDE.mdbecause it changes constantly: which blocks are implemented, which TODOs are open, where the code has drifted from spec, what the last 10 commits were, what design questions are blocking progress.
CLAUDE.md is the long-term memory. The context bundle is the short-term snapshot.
The workflow loop
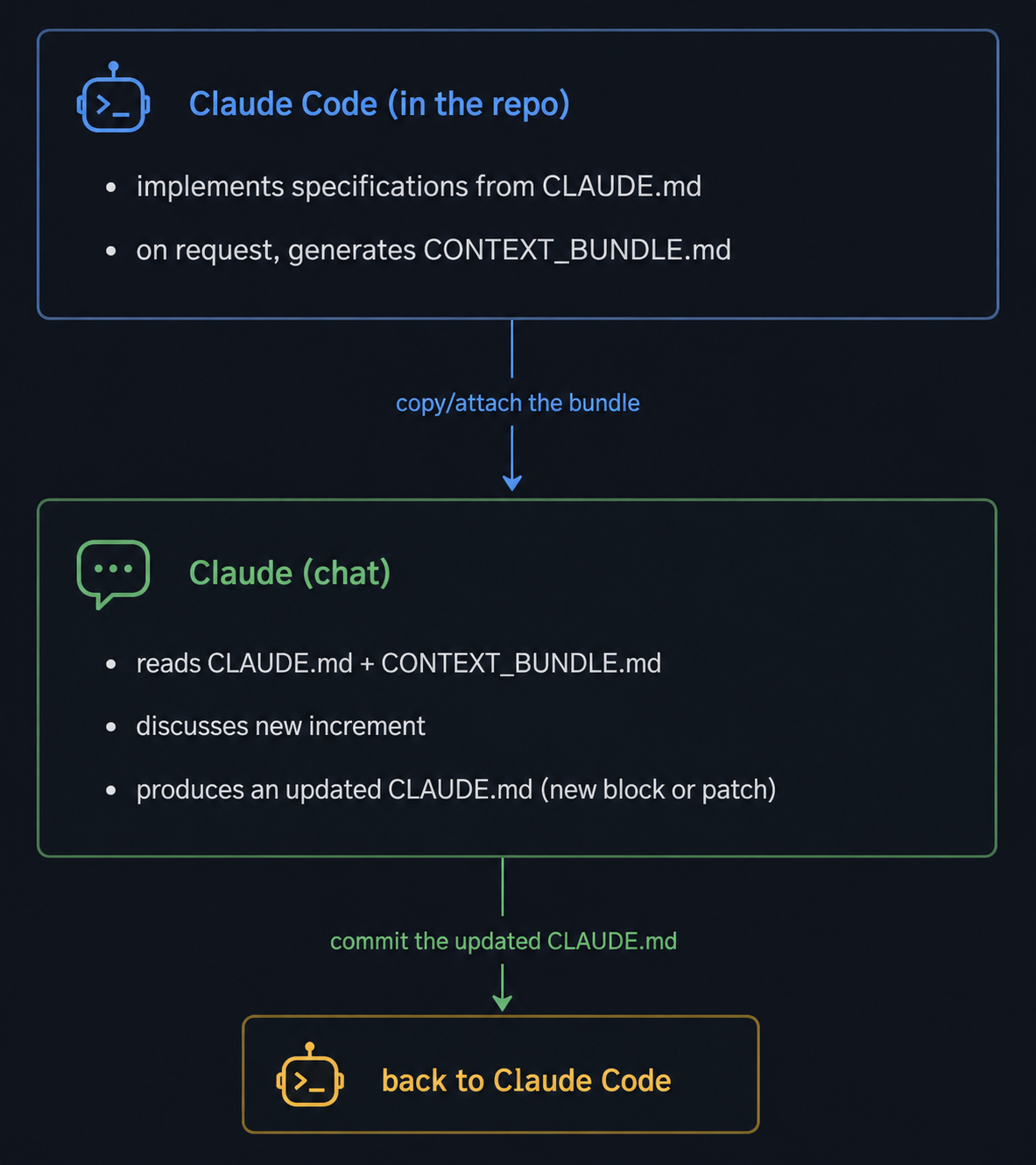
A typical iteration: I want to add a fourth pattern (say, a three-bar reversal). I open Claude Code, run the bundle command, get a snapshot of where the codebase actually is. I open chat, attach CLAUDE.md and the bundle, and write something like:
I want to add a
three_inside_uppattern (three-HA-bar reversal). Update Block 0 (config schema), Block 5 (detection), and Block 0.B (any new error codes). No code, only spec changes. Ask me anything you need first.
The chat session produces a diff against CLAUDE.md. I save it. I switch back to Claude Code and ask it to implement the changes. The specification stays the source of truth; the implementation follows.
Generating the bundle
The bundle command lives in CLAUDE.md itself, so Claude Code recognizes it consistently. The relevant section reads roughly:
## Generating a context bundle
When the operator says "context bundle" or "/context-bundle", produce
CONTEXT_BUNDLE.md in the repo root with these sections:
1. Project snapshot: name, version, last commit sha, date.
2. ADR summary: 5-line recap of the stack from CLAUDE.md.
3. Implementation status per block: not started | in progress | done | drifted.
4. Open TODOs: list of TODO/FIXME with file:line.
5. Known divergences from CLAUDE.md: decisions made during
implementation that contradict or extend the spec, with rationale.
6. Recent changes: last 10 git commits with one-line summaries.
7. Pending questions: open issues needing architectural input.
Keep the bundle under 500 lines. Print path and one-paragraph summary.
The most important section is divergences. The reality always betrays the spec; chat Claude needs to know where, otherwise it’ll propose solutions to problems already solved differently or insist on patterns the code has already moved past.
Lighter variants are useful too:
/status— just the implementation status, for a quick check./divergences— just the drift list, when you suspect things have wandered./open-questions— when you’re going to chat with one specific decision in mind.
The deployment question
A workflow involving Claude Code raises an immediate question: should Claude Code have AWS credentials? It’s a tool that can run shell commands. Giving it the keys lets it deploy directly. That sounds convenient. It’s a bad idea.
The right answer is: Claude Code prepares deployments, but doesn’t execute them. The actual terraform apply and Lambda update happen via GitHub Actions, triggered by a push to main, authenticated via OIDC federation rather than long-lived credentials.
| Pattern | Verdict |
|---|---|
AWS access keys in .env read by Claude Code |
bad. Long-lived credentials on disk, blast radius enormous if Claude Code runs the wrong command. |
| AWS SSO profile usable by Claude Code, including write access | bad. Bypasses CI audit and state lock. |
| AWS SSO profile, read-only, plus GitHub Actions for writes | good. Claude Code can run terraform plan, inspect logs, build artifacts. Cannot mutate prod. |
| GitHub Actions only, Claude Code never touches AWS | safest, but you lose the ability to plan and inspect locally. |
Option C is what I use. The CLAUDE.md includes an explicit deployment policy:
## Deployment policy
- Deploys happen exclusively via GitHub Actions on push to main, using
OIDC federation. See Block 9 for details.
- Local AWS access is read-only, via the `heikin-readonly` profile.
- You (Claude Code) MUST NOT run state-changing AWS commands:
no `terraform apply`, no `aws lambda update-function-code`,
no `aws s3 cp` to artifact buckets.
- You MAY run: `terraform plan`, `terraform fmt`, `terraform validate`,
`aws logs ...` (read), `aws lambda invoke` against dev sandboxes.
- To deploy, suggest a commit and push. Do not push without my confirmation.
That section sits at the same level as the architectural specifications. Claude Code respects it as part of the contract.
The bootstrap (creating the OIDC provider, the GitHub Actions role, the Terraform state bucket and lock table) is the one exception: it requires admin credentials, runs once, and is done by the human, not by any tool.
When the pattern fails
The previous post hinted that specifications consumed by LLMs are not documentation but executable belief. That observation has consequences here. The Two Claudes pattern is built on the assumption that CLAUDE.md accurately describes the system and remains synchronized with it. That assumption fails in three distinct ways, and each failure mode has a different remedy.
Specification entropy. Over time, decisions drift. The spec says “we use the de.sfuhrm:YahooFinanceAPI library”, but six months later the library has been quietly replaced by an Alpha Vantage adapter because Yahoo started rate-limiting more aggressively. The spec still claims the original choice. Chat Claude, asked to design a new feature involving market data, reasons inside the obsolete frame. The proposal it generates is internally coherent but inconsistent with the actual code. If I implement the proposal directly, I introduce a regression. If I notice the discrepancy and update the spec, I’ve spent a turn on housekeeping that should have been automatic.
The remedy is partial: periodic divergence audits (the context bundle helps, but only if I run it), explicit timestamps or “last verified” annotations on volatile sections, and a discipline of updating CLAUDE.md in the same commit as the code change, not later. None of these eliminate drift; they just shorten its half-life.
Spec inflation. The temptation, having seen the value of formalization, is to formalize more. Add another block. Add another GWT scenario. Add another anti-pattern to the code style section. Each addition is locally justified. Cumulatively, the spec grows past the point where I (the human) re-read it end to end before each session. Once that happens, I lose the ability to notice when sections become obsolete, because I’m no longer paying attention to most of them.
The remedy is harder: deliberate pruning. Sections that haven’t been consulted in months should be moved to an archive or deleted. Sections that the model interprets in surprising ways should be rewritten or removed. Treating the spec as accumulating and never shrinking is a recipe for it becoming the same kind of stale architecture document that lives in confluence and that nobody reads.
Synchronization debt. The two-Claudes loop assumes I run it consistently. If I make changes in Claude Code without going back to update CLAUDE.md, I accumulate debt that will eventually surface as confused chat sessions where the model proposes things that don’t fit. If I update CLAUDE.md from chat without then re-running the implementation in Claude Code, the spec describes a system that doesn’t exist yet. Both directions of sync failure are easy to commit and hard to detect until they cause pain.
The remedy is discipline that I haven’t fully built yet: changes are not done until both the spec and the code reflect them. This is the same discipline that documentation has always required, and that has historically failed for the same reasons. The difference is that with LLM-readable specs, the cost of failure is higher, because the next chat session reasons against the wrong artifact.
Where the pattern doesn’t apply at all
There’s a category of project the pattern simply doesn’t fit. These aren’t failure modes of the workflow; they’re conditions under which the workflow is the wrong tool entirely.
Exploratory work in unfamiliar domains. When you don’t yet know what you’re building, formalizing the structure too early ossifies the wrong shape. The spec becomes a commitment to a design you haven’t earned the right to make. In this regime, the right approach is to work fluidly with the LLM, accept that there’s no CLAUDE.md, iterate on prototypes, and only formalize once the shape has stabilized. Trying to apply the Two Claudes pattern before you have a clear picture of the system wastes effort and locks in poor decisions.
Systems with strong perceptual or aesthetic components. UX design, copy writing, visual design, anything where the truth of the artifact is judged by perception rather than by propositional correctness. Specifications work poorly here because the things that matter aren’t expressible in English. The Two Claudes pattern is optimized for systems where the spec can capture what matters; it degrades fast when it can’t.
Throwaway work. Scripts that run once. Prototypes that prove or disprove a hypothesis. One-shot data analysis. The setup cost of CLAUDE.md and a workflow loop is not worth it for work whose total duration is shorter than the setup. Use Claude Code directly. Skip the spec. Throw the script away when you’re done.
The general rule: the pattern’s value scales with project longevity, scope clarity, and the proportional weight of architectural decisions. For a year-long project with non-trivial structure, the overhead pays back many times over. For a script you write on a Tuesday and delete on Friday, the overhead is dead weight.
A note on per-product user preferences
Claude.ai’s user preferences and Claude Code’s project-level instructions overlap in purpose but live in different places. My recommendations:
- Global preferences in chat.com (Settings → Profile → User Preferences) cover behavior across all conversations: communication style, anti-patterns to avoid, formatting expectations. The retrospective post lists what I added after building this project.
- Per-project
CLAUDE.mdcovers the project. It goes in the repo root. Claude Code reads it automatically. Chat Claude reads it when you attach it. ~/.claude/CLAUDE.mdcan carry your personal cross-project instructions for Claude Code (testing preferences, commit message style, things you always want).
The split avoids putting project-specific things in your global config (which would pollute every project) and avoids putting personal stylistic preferences in CLAUDE.md (which would inflict them on collaborators).
In summary
Two Claudes, two roles, one shared memory (CLAUDE.md) and a regenerable snapshot (the context bundle). The chat surface holds the conversation; the code surface holds the work; the markdown files are how they communicate. Deployment goes through CI, not through either Claude directly. What the pattern can’t see — the gap between specification and running artifact — is the subject of Part 4.
The pattern works. It also has failure modes that compound silently and a domain of applicability that doesn’t include all software work. The discipline it requires is the discipline that documentation has always required, made more important by the fact that the documentation now reasons.
If I had to compress all three posts into one sentence: the AI tools change what’s worth formalizing and what isn’t, and the design judgment of when to invoke heavy structure versus when to skip it is increasingly the work that matters.